
Alternatively, they can trace links from one web site to another web site. This is the chief reason that is responsible for making inbound links to web sites extremely significant. If there are other websites that have got links to your particular website, then the spiders feed on this fact. The greater the number of times that they happen to come across links to your web site, the greater the number of times that they will pay a visit to your website. This is the way in which generally large indices of listings are generated.
While automated spider visits are the most common norm, if you have a new website, you can have a spider visit your website by simply submitting your website to your choice of directory. This method of manual submission of websites to a directory is a great way to have other directories, send their spiders to your website automatically, and it also helps if your website has good quality content. Submission or no submission, most spiders from most directories, will detect your site anyway and add it to their databases. This process is also known as spidering or crawling. This is a great way for directories to continually update their data.
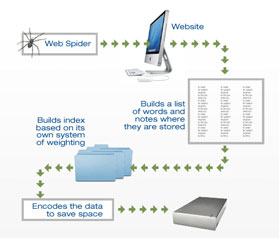
Spidering provides for easy creation, of copies of web pages followed, and subsequent indexing to enable quick search results. Spiders can additionally, be used to check for the error-free working of web page links or HTML codes. Also spiders help with the collection of particular types of data, such as email addresses for spamming purposes etc. The initial set of links with which a spider begins its tracing process, are termed as seeds. Once these initial set of links are visited, all the links within them are noted for the next round of visit.
This second set of links, are termed as the crawl frontier and these links are thereafter visited based on a body of policies. Some directories will give your website or web pages a very low ranking, if you use an invisible keyword. This is because the spider assumes an act of camouflaging and thereby an attempt on your part to fool the spider. If this is the kind of spider on the directory in which you intend to get listed and if invisible keywords are present on your web page, you will find very low visibility, and a resultant low number of web page visits, to your site from worldwide searches. Hence, it is best to avoid invisible coding.